Vibe coding is a modern day buzzword for prompt-driven, AI-assisted development. Over the last few years there has been an enormous push by companies to integrate “AI” into our everyday lives, with one of the controversial use-cases being software development. With AI models now being implemented by default in many IDEs the ease of AI assisted coding is now more accessible than ever.
Let’s take a look at what vibe coding means in terms of security. There aren’t any inherent issues with “vibe coding”, but it certainly changes things with threat modelling and understanding what’s going on behind the scenes.
What is Vibe Coding?
The simple answer is that vibe coding is a style of software development where people rely heavily on LLM models and AI tools to create and generate code. This type of software development is being used more and more by non-professional developers to create their own tools and even production apps and SaaS platforms to sell as a business.
What this is doing is shifting the scales a little by allowing more people to approach software development and to maybe get a foot in the door of making their product and business ideas come to life. To me, that’s a great thing.
However, from what I’ve read online there seems to be a general disdain of products that are built through vibe coding, and whether or not this is warranted is another matter of discussion.
Common Vibe Coding Security Issues
It isn’t all rainbows and smooth sailing, however, as there has been a fair few examples of startups and businesses (even high profile ones) seeing multiple security issues in their products that have been built rapidly as an MVP through vibe coding.
The main concern here is that people are building using AI to fully generate software in its entirety or to extend existing software with new features without ever reviewing the code or architecture that’s being created. Putting blind trust in a model that was trained on legacy, insecure, or outright poor code may result in a functional product that is not up to the expected security standard.
Below are some of the issues and areas of concern that organisations could face without being aware of the risks.
Implementation Awareness
Vibe coded startups, and even professional developers, may start using AI to generate code. They create the first piece of the puzzle, and then iterate on it through additional prompts and implement it.
Developers may end up knowing what the code does, but not how it works. This can lead to flaws creeping in either through continued advancements in best practices and the code not being updated to reflect this, insecure default settings not being adjusted and going unnoticed, or insecure libraries being included as per the LLM output.
Dependency Blindness & Supply Chain Attacks
The increased rate at which we’re now seeing supply chain attacks (especially with NPM this year) ties loosely to this. What if an AI suggested a vulnerable package and you or your developer imported and ran it on a production environment?
There’s also a concern of lookalike packages, where an incorrect malicious library is used instead of the genuine intended library. I’ve not seen this personally, but it should factor into any normal secure code review.
What has been visible, however, is that LLMs always seem to suggest the most appropriate library (Python, Node, etc) to minimise the code that it has to generate. In some cases this can be an unsupported library that hasn’t been updated or maintained in years – do you really want this running in production?
Generated Vulnerabilities at Scale
There’s no way around the fact that the “knowledge” an LLM can have is pre-baked and at a point-in-time. There are of course reasoning models that can take in new information (such as crawling a web page for data), but without specific prompting (and/or paying additionally for reasoning models) the code that is generated will be based upon data trained in the past.
With the massive amount of data that is on the net that is ripe for being used to train AIs there is obviously going to be a lot of poorly implemented, insecure, and legacy code. Unless you’re prompting the AI to include specific best practices, libraries, or functions, then it can be hit or miss as to whether you’ll get code that is based upon an 8 year old Stack Overflow post that “works” but isn’t secure.
Common Vulnerabilities
Hard coded secrets
Developers, especially those that are new to development through pure vibe coding, can often start building systems with inline hard-coded secrets (especially when starting a fresh project). API keys, database passwords, JWT signing keys, and cloud computing access keys are the most commonly seen secrets.
Committing this code to a repository leaves the secret in the git history, clearly accessible and visible to all. If the code is public in any way (such as a public repository, or being stored in the front-end code) then this is an instant way that developers or businesses can be compromised.
Insecure Cryptography
Code that is generated by AIs will often default to using weak or legacy cryptography as these are usually simple to implement and easy to understand. Outdated or no longer recommended hashing algorithms, such as SHA or Bcrypt, will usually be implemented for features like authentication, which goes against modern day best practices from OWASP.
If in some cases the AI uses encryption instead of hashing, or vice versa, for the less technical, newly designated software developers they may understand that “encryption is good” but not the context of what should happen behind the scenes, or understand any additional configuration options (such as salting, peppering, hash rounds, etc) that may be needed to be compliant to regulations or internal security policy.
Some additional examples may include:
- Weak algorithms used for hashing sensitive data (MD5, SHA1, etc)
- Symmetric encryption with reuse of keys or IVs
- Custom, non-standard implementations of cryptography functions (never roll your own!)
Lack of Input Validation / Sanitisation
One of the common weaknesses seen with application security, and it is still something that is seen all of the time during penetration testing, is where input validation is performed on the client side – and only the client side. Whilst this is important, it is crucial to ensure that is handled server-side (along with sanitisation).
In some cases AI may generate code with little or no validation, neither client-side or server-side. This code will usually “work” just fine, but validation and sanitisation add many layers of complexity to a piece of functionality and unless prompted to do so will omit them more often than not.
With client-side code, AIs sometimes do implement syntactic validation. This will check for and enforce the syntax of the respective fields (e.g. email format, telephone number, max length, etc).
Let’s take an example of an application that has been vibe coded, specifically a login mechanism.
If there is no server-side validation, but there is client-side validation, then a user that enters an incorrect email format may be warned directly in the UI without any requests being sent to the API. Nothing wrong with this, and warning early is a great practice.
However, an attacker could simply construct and send a custom HTTP request to the API by inserting malicious characters in the email field to attempt to cause SQL injection.
Some of the more common vulnerabilities caused by this include:
- File / path traversal
- SQL injection
- Authorisation bypass
- Command injection
Secure Coding Skills
Organisations that look to capitalise on the benefits of AI coding assistance can greatly increase the throughput of their development team – there is no doubt of the hightened efficiency here.
One of the biggest impacts to this could be that the organisation loses the ability to recognise insecure code at all.
- Junior developers could start to learn prompting rather than designing secure systems by default
- If the organisation pushes throughput too hard and there is no space for an internal review to plan and discuss the threat model of a new piece of functionality. This opens a security gap with unknown risks
Example of Vulnerabilities with Vibe Coding
Let’s take a minute to think about the general flow of data in a hypothetical application:
- A user visits a web app and signs up with an email and password
- The webapp sends this data to an API of some sort
- The API processes and stores the data in a database
- The user receives a success response (and likely an email confirming)
- The user logs in
Now, there’s a fair bit of architecture involved with just this flow. For one, there needs to be a front-end application (React, Angular, etc). Two, there should be a backend, like a serverless or hosted API. Finally, there needs to be a database of some kind to store the data. This is excluding anything else (like email or third-party services) just to keep it simple.
For a modern LLM it is relatively straight forward for it generate the code to handle all of this. I could put together some prompts and have something very basic running in a few short minutes. After all, the models have been trained on countless examples of code snippets and full projects that available online from GitHub, Stack Overflow, Reddit, and many more examples of sites where people will post code.
When prompting an AI to generate the code for this we’ll usually see some sort of common best practices come into play. I have no doubt that the LLMs have been trained on data from OWASP and that is clear to see with how the AI response will usually include some sort of password hashing, for example, or the occasional reference to OWASP itself.
Here’s an excerpt of a prompt response for generating a sign-up endpoint in a Python API:
In Python, generate an example API endpoint that processes a sign-up, stores the data in a database, and then sends a confirmation email to the user.class SignUpRequest(BaseModel):
email: EmailStr
password: str
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
email = Column(String, unique=True, index=True, nullable=False)
hashed_password = Column(String, nullable=False)
is_confirmed = Column(Boolean, default=False)
@app.post("/signup")
def signup(data: SignUpRequest, db: Session = Depends(get_db)):
existing_user = db.query(User).filter(User.email == data.email).first()
if existing_user:
raise HTTPException(status_code=400, detail="Email already registered")
hashed_password = hashlib.sha256(data.password.encode()).hexdigest()
user = User(
email=data.email,
hashed_password=hashed_password
)
db.add(user)
db.commit()
db.refresh(user)
send_confirmation_email(user.email)
return {
"message": "Sign-up successful. Please check your email to confirm your account."
}What issues spring to mind straight away?
- Username (email) enumeration in the 400 status response: “Email already registered”
- Password hashing using straight SHA256 rather than a KDF
- No input validation or sanitisation before interacting with the database
- A message sent to the UI to confirm the email, but there doesn’t seem to be any data, IDs, or unique keys supporting this in the code – the user would confirm their email by accessing a separate endpoint that would take in their email address rather than a unique and random key (note: this is not present here, but judging by the code this is what we’re led to believe)
Interestingly, the initial response from the AI states “This is illustrative (not production-ready), but follows common best practices.”, which is good to see but it does also falsely claims it follows common best practice. In a checkbox exercise this might pass, but realistically it does not align with modern-day security recommendations.
Moreso, what is also now frequently happening is that the AI will add additional information at the bottom to essentially prompt the user (!) as to what they could do next:
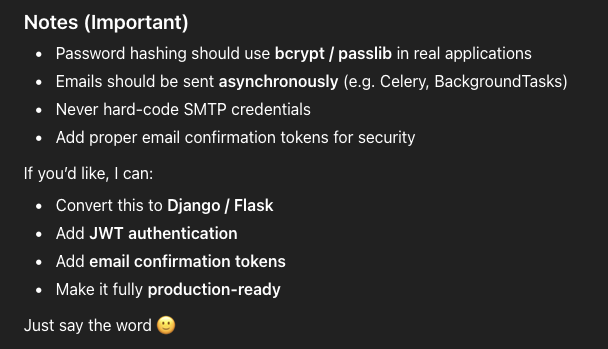
My main concern with this sort of process is that the additional ‘notes’ should have been incorporated by default. There’s an arugment here that doing this reduces the overhead for the AI (with token usage) and increases engagement from the user.
These additions in the ‘notes’ would have likely been included by default within the generated code if I’d have used some form of “make this production-ready” or “implement strong security practices”. But, this of course means that as a user I would have needed to know about what potential security issues there could be.
Additionally, the AI is recommending the use of bcrypt or passlib for password hashing – one of these is a hashing function the other is a library to support it in Python. As per OWASP Bcrypt is no longer recommended for modern applications (only for legacy/apps that cannot support modern algorithms like Argon2).
Guardrail Vibe Coding with Verification
So, what can be done by you or your developers to continue using AI to generate code but to do it in a safe, secure manner?
Human Code Review: Implement a strict security review of any code that is being implemented or merged. Whether this is a peer review or a self-review of your own code (as a solo developer), ensure that the code is understandable and that the logic, libraries, and any controls are understood.
Dependency Scanning: Many code repository services and cloud providers offer the ability to scan for dependencies within pushed code. GitHub, for example, provide this via their Dependabot, whilst certain IDEs include a check for vulnerable dependencies straight from the local interface even prior to the code being pushed.
SAST/DAST: Implementing automated security testing (both dynamic and static) can be a massive benefit to finding common issues that are easily able to be understood by automated scanners and to identify low-hanging vulnerabilities. Deploying this as part of the CI pipeline (e.g. on push or merge) will reduce the burden on developers when they are actively writing code.
Secret Scanning: Repository services like GitLab and GitHub offer secret scanning features as part of a subscription. Implementing secret scanning to prevent accidental pushes to a repository can prevent your secrets from being leaked, whilst secret detection can alert you immediately if a detected secret is found.
Secure Prompts: Work with, and not fight against, the use of AI for code generation by educating developers to start including certain phrases with their AI prompts. This can also be implemented in “system prompts” to reduce the overhead of having to write them manually. Phases such as “consider security implications” or “ensure any input is validated” are a good starting point.
Vibe Coding – Love It or Hate It?
There are certainly mixed opinions floating around about vibe coding.
Many experienced developers that have started to use AI for code generation have seen a net benefit to their efficiency, but say they always include targeted and detailed prompts, and try to avoid “overloading” any follow-up code change prompts by working on one thing at a time.
Others say that it can be useful for a proof of concept, but the time taken to review code and rework prompts can outweigh the time taken to just write the code directly.
Unfortunately, there’s nothing more permanent than a temporary solution. Organisations should make sure to allow developers and security teams the time and ability to implement and follow a secure software development lifecycle.
Is vibe coding bad? No, but if security isn’t part of the design and implementation philosophy there can be dire consequences. The last thing businesses or their users need is a security breach and a possible data leak.
One thing that is clear is that it’s excellent to see new people that may have had ambitions about creating software, but lacked the ability to do so, taking a step forward to start building their ideas. As a cybersecurity company Exploitr is happy to work with startups and organisations to provide secure code reviews and penetration testing, but as a security community we should look to support each other and those delving into this industry for the first time.
Get a quote today
Speak with our security team directly
Experts in providing thorough testing coverage
Fixed pricing with no surprises